
El miércoles 2 de agosto de 2023, Meta lanzó AudioCraft, un conjunto de herramientas de inteligencia artificial (IA) para crear música y audio a partir de mensajes de texto. Gracias a estas herramientas, los creadores de contenido pueden añadir descripciones de texto simples para crear paisajes sonoros complejos, componer melodías e incluso simular orquestas virtuales completas de manera sorprendente.
AudioCraft
AudioCraft tiene tres componentes principales que son: AudioGen, para generar efectos de audio y paisajes sonoros; MusicGen, que crea composiciones y melodías a partir de descripciones; y EnCodec, un códec de compresión de audio basado en redes neuronales.
Meta ha anunciado que ha realizado mejoras en EnCodec, una herramienta que permite generar música de mayor calidad con menos artefactos. Esta mejora ha sido reciente y ofrece la posibilidad de obtener un sonido más refinado. EnCodec fue mencionado por primera vez en noviembre y ha sido actualizado desde entonces.
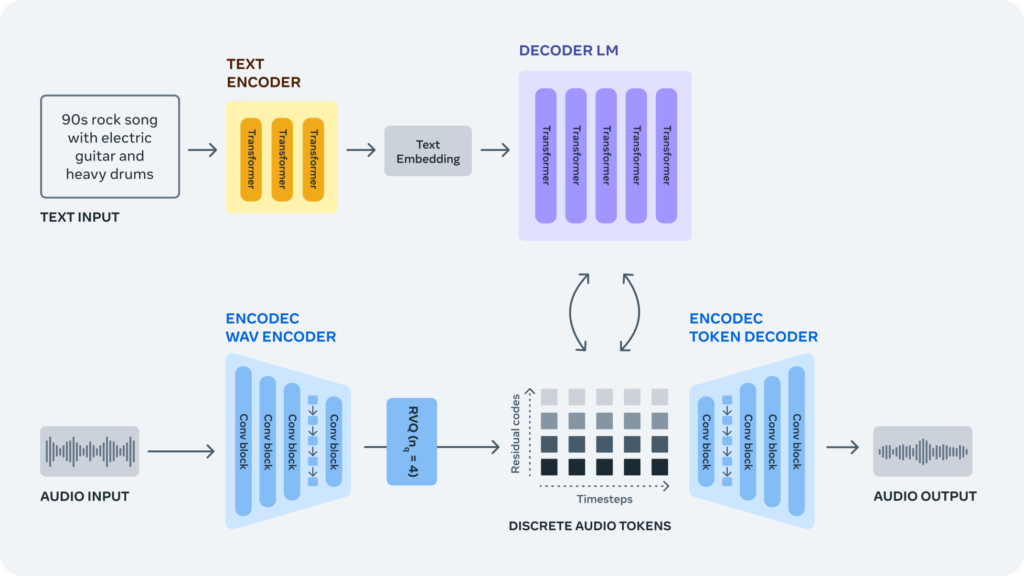
Además, AudioGen puede crear efectos de sonido como el ladrido de un perro, el claxon de un coche o pisadas en un suelo de madera. Con MusicGen, puedes generar increíbles canciones en diferentes géneros, partiendo desde cero. Solo necesitas describir lo que buscas en una prompt, como por ejemplo: “Una pegajosa pista de baile pop, con melodías cautivadoras, percusiones tropicales y ritmos alegres que te transportarán directamente a la playa”.
Y listo, audiocraft y su inteligencia artificial se encargará de crear la canción perfecta para ti.
Ecosistema Audiocraft
Meta ha facilitado varias muestras de audio en su sitio web para su evaluación. Aunque los resultados parecen coincidir con su enfoque vanguardista, se podría argumentar que aún no alcanzan la excelencia necesaria para reemplazar los efectos de audio o la música comercial producidos por profesionales.
Los modelos de IA generativa enfocados en texto e imágenes han sido muy populares y fáciles de probar en línea. Sin embargo, el desarrollo de herramientas de audio generativo ha sido más lento.”Hay algunos trabajos por ahí, pero son muy complicados y poco abiertos, así que la gente no puede jugar fácilmente con ellos”, escriben. Esperan que AudioCraft, con su publicación bajo la Licencia MIT, ayude a la comunidad al proporcionar herramientas accesibles para experimentar con la música y el sonido.
Los modelos están disponibles con fines de investigación y para que la gente conozca mejor la tecnología. Meta afirma estar muy satisfecha de permitir a investigadores y profesionales entrenar sus propios modelos utilizando sus propios conjuntos de datos, lo cual contribuirá al avance de la tecnología.

Meta no es la primera empresa que experimenta con generadores de audio y música basados en IA. Entre los intentos recientes más notables, OpenAI presentó su Jukebox en 2020, Google estrenó MusicLM en enero y, el pasado diciembre, un equipo de investigación independiente creó una plataforma de generación de texto a música llamada Riffusion utilizando una base de difusión estable.
Ninguno de estos proyectos de audio generativo ha atraído tanta atención como los modelos de síntesis de imágenes, pero eso no significa que el proceso de desarrollarlos no sea menos complicado, como señala Meta en su sitio web:
“Generar audio de alta fidelidad de cualquier tipo exige modelar señales y patrones complejos a distintas escalas.Podría decirse que la música es el tipo de audio más difícil de generar porque se compone de patrones locales y de largo alcance, desde un conjunto de notas hasta una estructura musical global con múltiples instrumentos. La generación de música coherente con IA se ha abordado a menudo mediante el uso de representaciones simbólicas como MIDI o rollos de piano.Sin embargo, estos enfoques son incapaces de captar plenamente los matices expresivos y los elementos estilísticos que se encuentran en la música. Los avances más recientes aprovechan el aprendizaje autosupervisado de representaciones de audio y una serie de modelos jerárquicos o en cascada para generar música, introduciendo el audio en bruto en un sistema complejo con el fin de captar las estructuras de largo alcance de la señal y generar al mismo tiempo audio de calidad. Pero sabíamos qué se podía hacer más en este campo.”
META
En medio de la controversia generada por el uso de material de entrenamiento no revelado y posiblemente poco ético para desarrollar modelos de síntesis de imagen como Stable Diffusion, DALL-E y Midjourney, es destacable que Meta afirme que MusicGen fue entrenado utilizando “20,000 horas de música propiedad de Meta o con licencia específica para este propósito”.A primera vista, parece un movimiento en una dirección más ética que puede complacer a algunos críticos de la IA generativa.
Será interesante ver cómo los desarrolladores de código abierto deciden integrar estos modelos de audio de Meta en su trabajo. Puede que en un futuro próximo surjan herramientas de audio generativo interesantes y fáciles de usar. Por ahora, los más expertos en código pueden encontrar los pesos de los modelos y el código de las tres herramientas AudioCraft en GitHub.
El paper por detrás de la tecnología puede ser descargado en Arxiv
Para oír más ejemplos de la tecnologia; clica aquí
